I am pleased to announce that a new release of the libvirt-glib package, version 5.0.0, is now available from
https://libvirt.org/sources/glib/
The packages are GPG signed with
Key fingerprint: DAF3 A6FD B26B 6291 2D0E 8E3F BE86 EBB4 1510 4FDF (4096R)
Changes in this release:
- Fix compatiblity with libxml2 >= 2.12.0
- Bump min libvirt version to 2.3.0
- Bump min meson to 0.56.0
- Require use of GCC >= 4.8 / CLang > 3.4 / XCode CLang > 5.1
- Mark USB disks as removable by default
- Add support for audio device backend config
- Add support for DBus graphics backend config
- Add support for controlling firmware feature flags
- Improve compiler flag handling in meson
- Extend library version script handling to FreeBSD
- Fix pointer sign issue in capabilities config API
- Fix compat with gnome.mkenums() in Meson 0.60.0
- Avoid compiler warnings from gi-ir-scanner generated code by not setting glib version constraints
- Be more robust about NULL GError parameters
- Disable unimportant cast alignment compiler warnings
- Use ‘pragma once’ in all header files
- Updated translations
Thanks to everyone who contributed to this new release.
The x86 platform has been ever so slowly moving towards a world where EFI is used to boot everything, with legacy BIOS put out to pasture. Virtual machines in general have been somewhat behind the cutting edge in this respect though. This has mostly been due to the virtualization and cloud platforms being somewhat slow in enabling use of EFI at all, let alone making it the default. In a great many cases the platforms still default to using BIOS unless explicitly asked to use EFI. With this in mind most the mainstream distros tend to provide general purpose disk images built such that they can boot under either BIOS or EFI, thus adapting to whatever environment the user deploys them in.
In recent times there is greater interest in the use of TPM sealing and SecureBoot for protecting guest secrets (eg LUKS passphrases), the introduction of UKIs as the means to extend the SecureBoot signature to close initrd/cmdline hole, and the advent of confidential virtualization technology. These all combine to increase the liklihood that a virtual machine image will exclusively target EFI, fully discontinuing support for legacy BIOS.
This presents a bit of a usability trapdoor for people deploying images though, as it has been taken for granted that BIOS boot always works. If one takes an EFI only disk image and attempts to boot it via legacy BIOS, the user is likely to get an entirely blank graphical display and/or serial console, with no obvious hint that EFI is required. Even if the requirement for EFI is documented, it is inevitable that users will make mistakes.
Can we do better than this ? Of course we can.
Enter ‘Bye Bye BIOS‘ (https://gitlab.com/berrange/byebyebios)
This is a simple command line tool that, when pointed to a disk image, will inject a MBR sector that prints out a message to the user on the primary VGA display and serial port informing them that UEFI is required, then puts the CPUs in a ‘hlt‘ loop.
The usage is as follows, with a guest serial port connected to the local terminal:
$ byebyebios test.img
$ qemu-system-x86_64 \
-blockdev driver=file,filename=test.img,node-name=img \
-device virtio-blk,drive=img \
-m 2000 -serial stdio
STOP: Machine was booted from BIOS or UEFI CSM
_ _ _ _ ___________ _____ ___
| \ | | | | | | ___| ___|_ _| |__ \
| \ | | ___ | | | | |__ | |_ | | ) |
| . ` |/ _ \ | | | | __|| _| | | / /
| |\ | (_) | | |_| | |___| | _| |_ |_|
\_| \_/ \___/ \___/\____/\_| \___/ (_)
Installation requires UEFI firmware to boot
Meanwhile the graphical console shows the same:
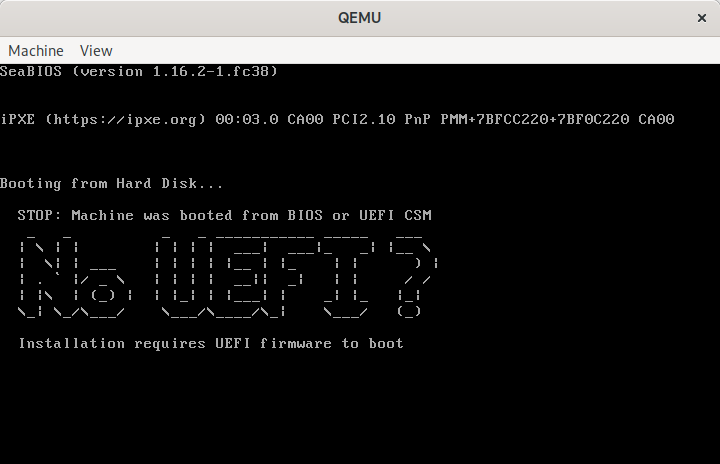
QEMU showing “No UEFI” message when booted from BIOS
The message shown here is a default, but it can be customized by pointing to an alternative message file
$ echo "Bye Bye BIOS" | figlet -f bubble | unix2dos > msg.txt
$ byebyebios --message msg.txt test.img
$ qemu-system-x86_64 \
-blockdev driver=file,filename=test.img,node-name=img \
-device virtio-blk,drive=img \
-m 2000 -serial stdio
_ _ _ _ _ _ _ _ _ _
/ \ / \ / \ / \ / \ / \ / \ / \ / \ / \
( B | y | e ) ( B | y | e ) ( B | I | O | S )
\_/ \_/ \_/ \_/ \_/ \_/ \_/ \_/ \_/ \_/
The code behind this is simplicity itself, just a short piece of x86 asm
$ cat bootstub.S
# SPDX-License-Identifier: MIT-0
.code16
.global bye_bye_bios
bye_bye_bios:
mov $something_important, %si
mov $0xe, %ah
mov $0x3f8,%dx
say_a_little_more:
lodsb
cmp $0, %al
je this_is_the_end
int $0x10
outb %al,%dx
jmp say_a_little_more
this_is_the_end:
hlt
jmp this_is_the_end
something_important:
# The string message will be appended here at time of install
This is compiled with the GNU assembler to create a i486 ELF object file
$ as -march i486 -mx86-used-note=no --32 -o bootstub.o bootstub.S
From this ELF object file we have to extract the raw machine code bytes
$ ld -m elf_i386 --oformat binary -e bye_bye_bios -Ttext 0x7c00 -o bootstub.bin bootstub.o
The byebyebios python tool takes this bootstub.bin, appends the text message and NUL terminator, padding to fill 446 bytes, then adds a dummy partition table and boot signature to fill the whole 512 sector.
With the boot stub binary at 21 bytes in size, this leaves 424 bytes available for the message to display to the user, which is ample for the purpose.
In conclusion, if you need to ship an EFI only virtual machine image, do your users a favour and use byebyebios to add a dummy MBR to tell them that the image is EFI only when they inevitably make a mistake and run it under legacy BIOS.
As a virtualization developer a significant amount of time is spent in understanding and debugging the behaviour and interaction of QEMU and the guest kernel/userspace code. As such my development machines have a variety of guest OS installations that get booted for various tasks. Some tasks, however, require a repeated cycle of QEMU code changes, or QEMU config changes, followed by guest testing. Waiting for an OS to boot can quickly become a significant time sink affecting productivity and lead to frustration. What is needed is a very low overhead way to accomplish simple testing tasks without an OS getting in the way.
Enter ‘make-tiny-image.py‘ tool for creating minimal initrd images.
If invoked with no arguments, this tool will create an initrd containing nothing more than busybox. The “init” program will be a script that creates a few device nodes, mounts proc/sysfs and then runs the busybox ‘sh’ binary to provide an interactive shell. This is intended to be used as follows
$ ./make-tiny-image.py
tiny-initrd.img
6.0.8-300.fc37.x86_64
$ qemu-system-x86_64 \
-kernel /boot/vmlinuz-$(uname -r) \
-initrd tiny-initrd.img \
-append 'console=ttyS0 quiet' \
-accel kvm -m 1000 -display none -serial stdio
~ # uname -a
Linux (none) 6.0.8-300.fc37.x86_64 #1 SMP PREEMPT_DYNAMIC Fri Nov 11 15:09:04 UTC 2022 x86_64 x86_64 x86_64 Linux
~ # uptime
15:05:42 up 0 min, load average: 0.00, 0.00, 0.00
~ # free
total used free shared buff/cache available
Mem: 961832 38056 911264 1388 12512 845600
Swap: 0 0 0
~ # df
Filesystem 1K-blocks Used Available Use% Mounted on
none 480916 0 480916 0% /dev
~ # ls
bin dev init proc root sys usr
~ # <Ctrl+D>
[ 23.841282] reboot: Power down
When I say “low overhead”, just how low are we talking about ? With KVM, it takes less than a second to bring up the shell. Testing with emulation is where this really shines. Booting a full Fedora OS with QEMU emulation is slow enough that you don’t want to do it at all frequently. With this tiny initrd, it’ll take a little under 4 seconds to boot to the interactive shell. Much slower than KVM, but fast enough you’ll be fine repeating this all day long, largely unaffected by the (lack of) speed relative to KVM.
The make-tiny-image.py tool will create the initrd such that it drops you into a shell, but it can be told to run another command instead. This is how I tested the overheads mentioned above
$ ./make-tiny-image.py --run poweroff
tiny-initrd.img
6.0.8-300.fc37.x86_64
$ time qemu-system-x86_64 \
-kernel /boot/vmlinuz-$(uname -r) \
-initrd tiny-initrd.img \
-append 'console=ttyS0 quiet' \
-m 1000 -display none -serial stdio -accel kvm
[ 0.561174] reboot: Power down
real 0m0.828s
user 0m0.613s
sys 0m0.093s
$ time qemu-system-x86_64 \
-kernel /boot/vmlinuz-$(uname -r) \
-initrd tiny-initrd.img \
-append 'console=ttyS0 quiet' \
-m 1000 -display none -serial stdio -accel tcg
[ 2.741983] reboot: Power down
real 0m3.774s
user 0m3.626s
sys 0m0.174s
As a more useful real world example, I wanted to test the effect of changing the QEMU CPU configuration against KVM and QEMU, by comparing at the guest /proc/cpuinfo.
$ ./make-tiny-image.py --run 'cat /proc/cpuinfo'
tiny-initrd.img
6.0.8-300.fc37.x86_64
$ qemu-system-x86_64 \
-kernel /boot/vmlinuz-$(uname -r) \
-initrd tiny-initrd.img \
-append 'console=ttyS0 quiet' \
-m 1000 -display none -serial stdio -accel tcg -cpu max | grep '^flags'
flags : fpu de pse tsc msr pae mce cx8 apic sep mtrr pge mca
cmov pat pse36 clflush acpi mmx fxsr sse sse2 ss syscall
nx mmxext pdpe1gb rdtscp lm 3dnowext 3dnow rep_good nopl
cpuid extd_apicid pni pclmulqdq monitor ssse3 cx16 sse4_1
sse4_2 movbe popcnt aes xsave rdrand hypervisor lahf_lm
svm cr8_legacy abm sse4a 3dnowprefetch vmmcall fsgsbase
bmi1 smep bmi2 erms mpx adx smap clflushopt clwb xsaveopt
xgetbv1 arat npt vgif umip pku ospke la57
$ qemu-system-x86_64 \
-kernel /boot/vmlinuz-$(uname -r) \
-initrd tiny-initrd.img \
-append 'console=ttyS0 quiet' \
-m 1000 -display none -serial stdio -accel kvm -cpu max | grep '^flags'
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca
cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx
pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good
nopl xtopology cpuid tsc_known_freq pni pclmulqdq vmx
ssse3 fma cx16 pdcm pcid sse4_1 sse4_2 x2apic movbe
popcnt tsc_deadline_timer aes xsave avx f16c rdrand
hypervisor lahf_lm abm 3dnowprefetch cpuid_fault
invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced
tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase
tsc_adjust sgx bmi1 avx2 smep bmi2 erms invpcid mpx
rdseed adx smap clflushopt xsaveopt xsavec xgetbv1
xsaves arat umip sgx_lc md_clear arch_capabilities
NB, with the list of flags above, I’ve manually line wrapped the output for saner presentation in this blog rather than have one giant long line.
These examples have relied on tools provided by busybox, but we’re not limited by that. It is possible to tell it to copy in arbitrary extra binaries from the host OS by just listing their name. If it is a dynamically linked ELF binary, it’ll follow the ELF header dependencies, pulling in any shared libraries needed.
$ ./make-tiny-image.py hwloc-info lstopo-no-graphics
tiny-initrd.img
6.0.8-300.fc37.x86_64
Copy bin /usr/bin/hwloc-info -> /tmp/make-tiny-imagexu_mqd99/bin/hwloc-info
Copy bin /usr/bin/lstopo-no-graphics -> /tmp/make-tiny-imagexu_mqd99/bin/lstopo-no-graphics
Copy lib /lib64/libhwloc.so.15 -> /tmp/make-tiny-imagexu_mqd99/lib64/libhwloc.so.15
Copy lib /lib64/libc.so.6 -> /tmp/make-tiny-imagexu_mqd99/lib64/libc.so.6
Copy lib /lib64/libm.so.6 -> /tmp/make-tiny-imagexu_mqd99/lib64/libm.so.6
Copy lib /lib64/ld-linux-x86-64.so.2 -> /tmp/make-tiny-imagexu_mqd99/lib64/ld-linux-x86-64.so.2
Copy lib /lib64/libtinfo.so.6 -> /tmp/make-tiny-imagexu_mqd99/lib64/libtinfo.so.6
$ qemu-system-x86_64 -kernel /boot/vmlinuz-$(uname -r) -initrd tiny-initrd.img -append 'console=ttyS0 quiet' -m 1000 -display none -serial stdio -accel kvm
~ # hwloc-info
depth 0: 1 Machine (type #0)
depth 1: 1 Package (type #1)
depth 2: 1 L3Cache (type #6)
depth 3: 1 L2Cache (type #5)
depth 4: 1 L1dCache (type #4)
depth 5: 1 L1iCache (type #9)
depth 6: 1 Core (type #2)
depth 7: 1 PU (type #3)
Special depth -3: 1 NUMANode (type #13)
Special depth -4: 1 Bridge (type #14)
Special depth -5: 3 PCIDev (type #15)
Special depth -6: 1 OSDev (type #16)
Special depth -7: 1 Misc (type #17)
~ # lstopo-no-graphics
Machine (939MB total)
Package L#0
NUMANode L#0 (P#0 939MB)
L3 L#0 (16MB) + L2 L#0 (4096KB) + L1d L#0 (32KB) + L1i L#0 (32KB) + Core L#0 + PU L#0 (P#0)
HostBridge
PCI 00:01.1 (IDE)
Block "sr0"
PCI 00:02.0 (VGA)
PCI 00:03.0 (Ethernet)
Misc(MemoryModule)
An obvious limitation is that if the binary/library requires certain data files, those will not be present in the initrd. It isn’t attempting to do anything clever like query the corresponding RPM file list and copy those. This tool is meant to be simple and fast and keep out of your way. If certain data files are critical for testing though, the --copy argument can be used. The copied files will be put at the same path inside the initrd as found on the host
$ ./make-tiny-image.py --copy /etc/redhat-release
tiny-initrd.img
6.0.8-300.fc37.x86_64
Copy extra /etc/redhat-release -> /tmp/make-tiny-imageicj1tvq4/etc/redhat-release
$ qemu-system-x86_64 \
-kernel /boot/vmlinuz-$(uname -r) \
-initrd tiny-initrd.img \
-append 'console=ttyS0 quiet' \
-m 1000 -display none -serial stdio -accel kvm
~ # cat /etc/redhat-release
Fedora release 37 (Thirty Seven)
What if the problem being tested requires using some kernel modules ? That’s covered too with the --kmod argument, which will copy in the modules listed, along with their dependencies and the insmod command itself. As an example of its utility, I used this recently to debug a regression in support for the iTCO watchdog in Linux kernels
$ ./make-tiny-image.py --kmod lpc_ich --kmod iTCO_wdt --kmod i2c_i801
tiny-initrd.img
6.0.8-300.fc37.x86_64
Copy kmod /lib/modules/6.0.8-300.fc37.x86_64/kernel/drivers/mfd/lpc_ich.ko.xz -> /tmp/make-tiny-image63td8wbl/lib/modules/lpc_ich.ko.xz
Copy kmod /lib/modules/6.0.8-300.fc37.x86_64/kernel/drivers/watchdog/iTCO_wdt.ko.xz -> /tmp/make-tiny-image63td8wbl/lib/modules/iTCO_wdt.ko.xz
Copy kmod /lib/modules/6.0.8-300.fc37.x86_64/kernel/drivers/watchdog/iTCO_vendor_support.ko.xz -> /tmp/make-tiny-image63td8wbl/lib/modules/iTCO_vendor_support.ko.xz
Copy kmod /lib/modules/6.0.8-300.fc37.x86_64/kernel/drivers/mfd/intel_pmc_bxt.ko.xz -> /tmp/make-tiny-image63td8wbl/lib/modules/intel_pmc_bxt.ko.xz
Copy kmod /lib/modules/6.0.8-300.fc37.x86_64/kernel/drivers/i2c/busses/i2c-i801.ko.xz -> /tmp/make-tiny-image63td8wbl/lib/modules/i2c-i801.ko.xz
Copy kmod /lib/modules/6.0.8-300.fc37.x86_64/kernel/drivers/i2c/i2c-smbus.ko.xz -> /tmp/make-tiny-image63td8wbl/lib/modules/i2c-smbus.ko.xz
Copy bin /usr/sbin/insmod -> /tmp/make-tiny-image63td8wbl/bin/insmod
Copy lib /lib64/libzstd.so.1 -> /tmp/make-tiny-image63td8wbl/lib64/libzstd.so.1
Copy lib /lib64/liblzma.so.5 -> /tmp/make-tiny-image63td8wbl/lib64/liblzma.so.5
Copy lib /lib64/libz.so.1 -> /tmp/make-tiny-image63td8wbl/lib64/libz.so.1
Copy lib /lib64/libcrypto.so.3 -> /tmp/make-tiny-image63td8wbl/lib64/libcrypto.so.3
Copy lib /lib64/libgcc_s.so.1 -> /tmp/make-tiny-image63td8wbl/lib64/libgcc_s.so.1
Copy lib /lib64/libc.so.6 -> /tmp/make-tiny-image63td8wbl/lib64/libc.so.6
Copy lib /lib64/ld-linux-x86-64.so.2 -> /tmp/make-tiny-image63td8wbl/lib64/ld-linux-x86-64.so.2
$ ~/src/virt/qemu/build/qemu-system-x86_64 -kernel /boot/vmlinuz-$(uname -r) -initrd tiny-initrd.img -append 'console=ttyS0 quiet' -m 1000 -display none -serial stdio -accel kvm -M q35 -global ICH9-LPC.noreboot=false -watchdog-action poweroff -trace ich9* -trace tco*
ich9_cc_read addr=0x3410 val=0x20 len=4
ich9_cc_write addr=0x3410 val=0x0 len=4
ich9_cc_read addr=0x3410 val=0x0 len=4
ich9_cc_read addr=0x3410 val=0x0 len=4
ich9_cc_write addr=0x3410 val=0x20 len=4
ich9_cc_read addr=0x3410 val=0x20 len=4
tco_io_write addr=0x4 val=0x8
tco_io_write addr=0x6 val=0x2
tco_io_write addr=0x6 val=0x4
tco_io_read addr=0x8 val=0x0
tco_io_read addr=0x12 val=0x4
tco_io_write addr=0x12 val=0x32
tco_io_read addr=0x12 val=0x32
tco_io_write addr=0x0 val=0x1
tco_timer_reload ticks=50 (30000 ms)
~ # mknod /dev/watchdog0 c 10 130
~ # cat /dev/watchdog0
tco_io_write addr=0x0 val=0x1
tco_timer_reload ticks=50 (30000 ms)
cat: read error: Invalid argument
[ 11.052062] watchdog: watchdog0: watchdog did not stop!
tco_io_write addr=0x0 val=0x1
tco_timer_reload ticks=50 (30000 ms)
~ # tco_timer_expired timeouts_no=0 no_reboot=0/1
tco_timer_reload ticks=50 (30000 ms)
tco_timer_expired timeouts_no=1 no_reboot=0/1
tco_timer_reload ticks=50 (30000 ms)
tco_timer_expired timeouts_no=0 no_reboot=0/1
tco_timer_reload ticks=50 (30000 ms)
The Linux regression had accidentally left the watchdog with the ‘no reboot’ bit set, so it would never trigger the action, which we diagnosed from seeing repeated QEMU trace events for tco_timer_expired after triggering the watchdog in the guest. This was quicky fixed by the Linux maintainers.
In spite of being such a simple and crude script, with many, many, many unhandled edge cases, it has proved remarkably useful at enabling low overhead debugging of QEMU/Linux guest behaviour.
A recent thread on the Fedora development list about unified kernel images co-incided with work I’m involved in wrt confidential computing (AMD SEV[-SNP], Intel TDX, etc). In exploring the different options for booting virtual machines in a confidential computing environment, one of the problems that keeps coming up is that of validating the boot measurements of the initrd and kernel command line. The initrd is currently generated on the fly at the time the kernel is installed on a host, while the command line typically contains host specific UUIDs for filesystems or LUKS volumes. Before even dealing with those problems, grub2‘s support for TPMs causes pain due to its need to measure every single grub.conf configuration line that is executed into a PCR. Even with the most minimal grub.conf using autodiscovery based on the boot loader spec, the grub.conf boot measurements are horribly cumbersome to deal with.
With this in mind, in working on confidential virtualization, we’re exploring options for simplifying the boot process by eliminating any per-host variable measurements. A promising way of achieving this is to make use of sd-boot instead of grub2, and using unified kernel images pre-built and signed by the OS vendor. I don’t have enough familiarity with this area of Linux, so I’ve been spending time trying out the different options available to better understand their operation. What follows is a short description of how i took an existing Fedora 36 virtual machine and converted it to sd-boot with a unified kernel image.
First of all, I’m assuming that the virtual machine has been installed using UEFI (EDK2’s OOVMF build) as the firmware, rather than legacy BIOS (aka SeaBIOS). This is not the default with virt-manager/virt-install, but an opt-in is possible at time of provisioning the guest. Similarly it is possible to opt-in to adding a virtual TPM to the guest, for the purpose of receiving boot measurements. Latest upstream code for virt-manager/virt-install will always add a vTPM if UEFI is requested.
Assuming UEFI + vTPM are enabled for the guest, the default Fedora / RHEL setup will also result in SecureBoot being enabled in the guest. This is good in general, but the sd-boot shipped in Fedora is not currently signed. Thus for (current) testing, either disable SecureBoot, or manually sign the sd-boot binary with a local key and enroll that key with UEFI. SecureBoot isn’t immediately important, so the quickest option is disabling SecureBoot with the following libvirt guest XML config setup:
<os firmware='efi'>
<type arch='x86_64' machine='pc-q35-6.2'>hvm</type>
<firmware>
<feature enabled='no' name='secure-boot'/>
</firmware>
<loader secure='no'/>
<boot dev='hd'/>
</os>
The next time the guest is cold-booted, the ‘--reset-nvram‘ flag needs to be passed to ‘virsh start‘ to make it throwaway the existing SecureBoot enabled NVRAM and replace it with one disabling SecureBoot.
$ virsh start --reset-nvram fedora36test
Inside the guest, surprisingly, there were only two steps required, installing ‘sd-boot’ to the EFI partition, and building the unified kernel images. Installing ‘sd-boot’ will disable the use of grub, so don’t reboot after this first step, until the kernels are setup:
$ bootctl install
Created "/boot/efi/EFI/systemd".
Created "/boot/efi/loader".
Created "/boot/efi/loader/entries".
Created "/boot/efi/EFI/Linux".
Copied "/usr/lib/systemd/boot/efi/systemd-bootx64.efi" to "/boot/efi/EFI/systemd/systemd-bootx64.efi".
Copied "/usr/lib/systemd/boot/efi/systemd-bootx64.efi" to "/boot/efi/EFI/BOOT/BOOTX64.EFI".
Updated /etc/machine-info with KERNEL_INSTALL_LAYOUT=bls
Random seed file /boot/efi/loader/random-seed successfully written (512 bytes).
Not installing system token, since we are running in a virtualized environment.
Created EFI boot entry "Linux Boot Manager".
While the ‘/boot/efi/loader‘ directory could be populated with config files specifying kernel/initrd/cmdline to boot, the desire is to be able to demonstrate booting with zero host local configuration. So the next step is to build and install the unified kernel image. The Arch Linux wiki has a comprehensive guide, but the easiest option for Fedora appears to be to use dracut with its ‘--uefi‘ flag
$ for i in /boot/vmlinuz-*x86_64
do
kver=${i#/boot/vmlinuz-}
echo "Generating $kver"
dracut --uefi --kver $kver --kernel-cmdline "root=UUID=5fd49e99-6297-4880-92ef-bc31aef6d2f0 ro rd.luks.uuid=luks-6806c81d-4169-4e7a-9bbc-c7bf65cabcb2 rhgb quiet"
done
Generating 5.17.13-300.fc36.x86_64
Generating 5.17.5-300.fc36.x86_64
The observant will notice the ‘–kernel-cmdline’ argument refers to install specific UUIDs for the LUKS volume and root filesystem. This ultimately needs to be eliminated too, which would require configuring the guest disk image to comply with the discoverable partitions spec. That is beyond the scope of my current exercise of merely demonstrating use of sd-boot and unified kernels. It ought to be possible to write a kickstart file to automate creation of a suitable cloud image though.
At this point the VM is rebooted, and watching the graphical console confirms that the grub menu has disappeared and display output goes straight from the UEFI splash screen into Linux. There’s no menu shown by sd-boot by default, but if desired this can be enabled by editing /boot/efi/loader/loader.conf to uncomment the line timeout 3, at which point it will show the kernel version selection at boot.
If following this scheme, bear in mind that nothing is wired up to handle this during kernel updates. The kernel RPM triggers will continue to setup grub.conf and generate standalone initrds. IOW don’t try this on a VM that you care about. I assume there’s some set of commands I could use to uninstall sd-boot and switch back to grub, but I’ve not bothered to figure this out.
Overall this exercise was suprisingly simple and painless. The whole idea of using a drastically simplified boot loader instead of grub, along with pre-built unified kernel images, feels like it has alot of promise, especially in the context of virtual machines where the set of possible boot hardware variants is small and well understood.
I am happy to announce a new bugfix release of virt-viewer 10.0 (gpg), including experimental Windows installers for Win x86 MSI (gpg) and Win x64 MSI (gpg).
Signatures are created with key DAF3 A6FD B26B 6291 2D0E 8E3F BE86 EBB4 1510 4FDF (4096R)
With this release the project replaced the autotools build system with Meson and Ninja and re-designed the user interface to eliminate the menu bar
All historical releases are available from:
http://virt-manager.org/download/
Changes in this release include:
- Switch to use Meson for build system instead of autotools
- Require libvirt >= 1.2.8
- Redesign UI to use title bar widget instead of menu bar
- Request use of dark theme by default, if available
- Don’t filter out oVirt DATA storage domains for ISO image sharing
- Add –keymap arg to allow keys to be remapped
- Display error message if no extension is present for screenshot filename
- Fix misc memory leaks
- Use nicer error message if not ISOs are available
- Use more explicit accelerator hint to distinguish left and right ctrl/alt keys
- Report detailed file transfer errors
- Use standard about diaglog
- Refresh and improve translations
- Install appstream data file in preferred location
- Refresh appstream data file contents
- Display VM title when listing VMs, if available
- Display VM description as tooltop, if available
- Sort VM names when listing
- Enable ASLR and NX for Windows builds
- Add –shared arg to request a shared session for VNC
- Disable all accels when not grabbed in kiosk mode
- Allow num keypad to be used for zoom changes
- Disable grab sequence in kiosk mode to prevent escape
- Allow zoom hotkeys to be set on the command line / vv file
- Display error message if VNC connection fails
- Fix warnings about atomics with new GLib
- Remove use of deprecated GTK APIs
- Document cursor ungrab sequence in man pages
- Honour Ctrl-C when auth dialog is active
- Minor UI tweaks to auth dialog
- Support VM power control actions with VNC
- Add –cursor arg to control whether a local pointer is rendered with VNC
- Add –auto-resize arg and menu to control whether to resize the remote framebuffer to math local window size
- Add support for remote framebuffer resize with VNC
- Handle case sensitivity when parsing accelerator mappings