The x86 platform has been ever so slowly moving towards a world where EFI is used to boot everything, with legacy BIOS put out to pasture. Virtual machines in general have been somewhat behind the cutting edge in this respect though. This has mostly been due to the virtualization and cloud platforms being somewhat slow in enabling use of EFI at all, let alone making it the default. In a great many cases the platforms still default to using BIOS unless explicitly asked to use EFI. With this in mind most the mainstream distros tend to provide general purpose disk images built such that they can boot under either BIOS or EFI, thus adapting to whatever environment the user deploys them in.
In recent times there is greater interest in the use of TPM sealing and SecureBoot for protecting guest secrets (eg LUKS passphrases), the introduction of UKIs as the means to extend the SecureBoot signature to close initrd/cmdline hole, and the advent of confidential virtualization technology. These all combine to increase the liklihood that a virtual machine image will exclusively target EFI, fully discontinuing support for legacy BIOS.
This presents a bit of a usability trapdoor for people deploying images though, as it has been taken for granted that BIOS boot always works. If one takes an EFI only disk image and attempts to boot it via legacy BIOS, the user is likely to get an entirely blank graphical display and/or serial console, with no obvious hint that EFI is required. Even if the requirement for EFI is documented, it is inevitable that users will make mistakes.
Can we do better than this ? Of course we can.
Enter ‘Bye Bye BIOS‘ (https://gitlab.com/berrange/byebyebios)
This is a simple command line tool that, when pointed to a disk image, will inject a MBR sector that prints out a message to the user on the primary VGA display and serial port informing them that UEFI is required, then puts the CPUs in a ‘hlt‘ loop.
The usage is as follows, with a guest serial port connected to the local terminal:
$ byebyebios test.img
$ qemu-system-x86_64 \
-blockdev driver=file,filename=test.img,node-name=img \
-device virtio-blk,drive=img \
-m 2000 -serial stdio
STOP: Machine was booted from BIOS or UEFI CSM
_ _ _ _ ___________ _____ ___
| \ | | | | | | ___| ___|_ _| |__ \
| \ | | ___ | | | | |__ | |_ | | ) |
| . ` |/ _ \ | | | | __|| _| | | / /
| |\ | (_) | | |_| | |___| | _| |_ |_|
\_| \_/ \___/ \___/\____/\_| \___/ (_)
Installation requires UEFI firmware to boot
Meanwhile the graphical console shows the same:
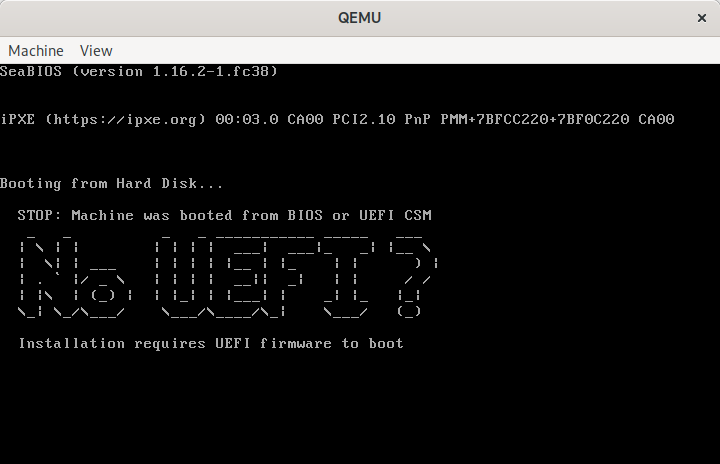
QEMU showing “No UEFI” message when booted from BIOS
The message shown here is a default, but it can be customized by pointing to an alternative message file
$ echo "Bye Bye BIOS" | figlet -f bubble | unix2dos > msg.txt
$ byebyebios --message msg.txt test.img
$ qemu-system-x86_64 \
-blockdev driver=file,filename=test.img,node-name=img \
-device virtio-blk,drive=img \
-m 2000 -serial stdio
_ _ _ _ _ _ _ _ _ _
/ \ / \ / \ / \ / \ / \ / \ / \ / \ / \
( B | y | e ) ( B | y | e ) ( B | I | O | S )
\_/ \_/ \_/ \_/ \_/ \_/ \_/ \_/ \_/ \_/
The code behind this is simplicity itself, just a short piece of x86 asm
$ cat bootstub.S
# SPDX-License-Identifier: MIT-0
.code16
.global bye_bye_bios
bye_bye_bios:
mov $something_important, %si
mov $0xe, %ah
mov $0x3f8,%dx
say_a_little_more:
lodsb
cmp $0, %al
je this_is_the_end
int $0x10
outb %al,%dx
jmp say_a_little_more
this_is_the_end:
hlt
jmp this_is_the_end
something_important:
# The string message will be appended here at time of install
This is compiled with the GNU assembler to create a i486 ELF object file
$ as -march i486 -mx86-used-note=no --32 -o bootstub.o bootstub.S
From this ELF object file we have to extract the raw machine code bytes
$ ld -m elf_i386 --oformat binary -e bye_bye_bios -Ttext 0x7c00 -o bootstub.bin bootstub.o
The byebyebios python tool takes this bootstub.bin, appends the text message and NUL terminator, padding to fill 446 bytes, then adds a dummy partition table and boot signature to fill the whole 512 sector.
With the boot stub binary at 21 bytes in size, this leaves 424 bytes available for the message to display to the user, which is ample for the purpose.
In conclusion, if you need to ship an EFI only virtual machine image, do your users a favour and use byebyebios to add a dummy MBR to tell them that the image is EFI only when they inevitably make a mistake and run it under legacy BIOS.
As a virtualization developer a significant amount of time is spent in understanding and debugging the behaviour and interaction of QEMU and the guest kernel/userspace code. As such my development machines have a variety of guest OS installations that get booted for various tasks. Some tasks, however, require a repeated cycle of QEMU code changes, or QEMU config changes, followed by guest testing. Waiting for an OS to boot can quickly become a significant time sink affecting productivity and lead to frustration. What is needed is a very low overhead way to accomplish simple testing tasks without an OS getting in the way.
Enter ‘make-tiny-image.py‘ tool for creating minimal initrd images.
If invoked with no arguments, this tool will create an initrd containing nothing more than busybox. The “init” program will be a script that creates a few device nodes, mounts proc/sysfs and then runs the busybox ‘sh’ binary to provide an interactive shell. This is intended to be used as follows
$ ./make-tiny-image.py
tiny-initrd.img
6.0.8-300.fc37.x86_64
$ qemu-system-x86_64 \
-kernel /boot/vmlinuz-$(uname -r) \
-initrd tiny-initrd.img \
-append 'console=ttyS0 quiet' \
-accel kvm -m 1000 -display none -serial stdio
~ # uname -a
Linux (none) 6.0.8-300.fc37.x86_64 #1 SMP PREEMPT_DYNAMIC Fri Nov 11 15:09:04 UTC 2022 x86_64 x86_64 x86_64 Linux
~ # uptime
15:05:42 up 0 min, load average: 0.00, 0.00, 0.00
~ # free
total used free shared buff/cache available
Mem: 961832 38056 911264 1388 12512 845600
Swap: 0 0 0
~ # df
Filesystem 1K-blocks Used Available Use% Mounted on
none 480916 0 480916 0% /dev
~ # ls
bin dev init proc root sys usr
~ # <Ctrl+D>
[ 23.841282] reboot: Power down
When I say “low overhead”, just how low are we talking about ? With KVM, it takes less than a second to bring up the shell. Testing with emulation is where this really shines. Booting a full Fedora OS with QEMU emulation is slow enough that you don’t want to do it at all frequently. With this tiny initrd, it’ll take a little under 4 seconds to boot to the interactive shell. Much slower than KVM, but fast enough you’ll be fine repeating this all day long, largely unaffected by the (lack of) speed relative to KVM.
The make-tiny-image.py tool will create the initrd such that it drops you into a shell, but it can be told to run another command instead. This is how I tested the overheads mentioned above
$ ./make-tiny-image.py --run poweroff
tiny-initrd.img
6.0.8-300.fc37.x86_64
$ time qemu-system-x86_64 \
-kernel /boot/vmlinuz-$(uname -r) \
-initrd tiny-initrd.img \
-append 'console=ttyS0 quiet' \
-m 1000 -display none -serial stdio -accel kvm
[ 0.561174] reboot: Power down
real 0m0.828s
user 0m0.613s
sys 0m0.093s
$ time qemu-system-x86_64 \
-kernel /boot/vmlinuz-$(uname -r) \
-initrd tiny-initrd.img \
-append 'console=ttyS0 quiet' \
-m 1000 -display none -serial stdio -accel tcg
[ 2.741983] reboot: Power down
real 0m3.774s
user 0m3.626s
sys 0m0.174s
As a more useful real world example, I wanted to test the effect of changing the QEMU CPU configuration against KVM and QEMU, by comparing at the guest /proc/cpuinfo.
$ ./make-tiny-image.py --run 'cat /proc/cpuinfo'
tiny-initrd.img
6.0.8-300.fc37.x86_64
$ qemu-system-x86_64 \
-kernel /boot/vmlinuz-$(uname -r) \
-initrd tiny-initrd.img \
-append 'console=ttyS0 quiet' \
-m 1000 -display none -serial stdio -accel tcg -cpu max | grep '^flags'
flags : fpu de pse tsc msr pae mce cx8 apic sep mtrr pge mca
cmov pat pse36 clflush acpi mmx fxsr sse sse2 ss syscall
nx mmxext pdpe1gb rdtscp lm 3dnowext 3dnow rep_good nopl
cpuid extd_apicid pni pclmulqdq monitor ssse3 cx16 sse4_1
sse4_2 movbe popcnt aes xsave rdrand hypervisor lahf_lm
svm cr8_legacy abm sse4a 3dnowprefetch vmmcall fsgsbase
bmi1 smep bmi2 erms mpx adx smap clflushopt clwb xsaveopt
xgetbv1 arat npt vgif umip pku ospke la57
$ qemu-system-x86_64 \
-kernel /boot/vmlinuz-$(uname -r) \
-initrd tiny-initrd.img \
-append 'console=ttyS0 quiet' \
-m 1000 -display none -serial stdio -accel kvm -cpu max | grep '^flags'
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca
cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx
pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good
nopl xtopology cpuid tsc_known_freq pni pclmulqdq vmx
ssse3 fma cx16 pdcm pcid sse4_1 sse4_2 x2apic movbe
popcnt tsc_deadline_timer aes xsave avx f16c rdrand
hypervisor lahf_lm abm 3dnowprefetch cpuid_fault
invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced
tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase
tsc_adjust sgx bmi1 avx2 smep bmi2 erms invpcid mpx
rdseed adx smap clflushopt xsaveopt xsavec xgetbv1
xsaves arat umip sgx_lc md_clear arch_capabilities
NB, with the list of flags above, I’ve manually line wrapped the output for saner presentation in this blog rather than have one giant long line.
These examples have relied on tools provided by busybox, but we’re not limited by that. It is possible to tell it to copy in arbitrary extra binaries from the host OS by just listing their name. If it is a dynamically linked ELF binary, it’ll follow the ELF header dependencies, pulling in any shared libraries needed.
$ ./make-tiny-image.py hwloc-info lstopo-no-graphics
tiny-initrd.img
6.0.8-300.fc37.x86_64
Copy bin /usr/bin/hwloc-info -> /tmp/make-tiny-imagexu_mqd99/bin/hwloc-info
Copy bin /usr/bin/lstopo-no-graphics -> /tmp/make-tiny-imagexu_mqd99/bin/lstopo-no-graphics
Copy lib /lib64/libhwloc.so.15 -> /tmp/make-tiny-imagexu_mqd99/lib64/libhwloc.so.15
Copy lib /lib64/libc.so.6 -> /tmp/make-tiny-imagexu_mqd99/lib64/libc.so.6
Copy lib /lib64/libm.so.6 -> /tmp/make-tiny-imagexu_mqd99/lib64/libm.so.6
Copy lib /lib64/ld-linux-x86-64.so.2 -> /tmp/make-tiny-imagexu_mqd99/lib64/ld-linux-x86-64.so.2
Copy lib /lib64/libtinfo.so.6 -> /tmp/make-tiny-imagexu_mqd99/lib64/libtinfo.so.6
$ qemu-system-x86_64 -kernel /boot/vmlinuz-$(uname -r) -initrd tiny-initrd.img -append 'console=ttyS0 quiet' -m 1000 -display none -serial stdio -accel kvm
~ # hwloc-info
depth 0: 1 Machine (type #0)
depth 1: 1 Package (type #1)
depth 2: 1 L3Cache (type #6)
depth 3: 1 L2Cache (type #5)
depth 4: 1 L1dCache (type #4)
depth 5: 1 L1iCache (type #9)
depth 6: 1 Core (type #2)
depth 7: 1 PU (type #3)
Special depth -3: 1 NUMANode (type #13)
Special depth -4: 1 Bridge (type #14)
Special depth -5: 3 PCIDev (type #15)
Special depth -6: 1 OSDev (type #16)
Special depth -7: 1 Misc (type #17)
~ # lstopo-no-graphics
Machine (939MB total)
Package L#0
NUMANode L#0 (P#0 939MB)
L3 L#0 (16MB) + L2 L#0 (4096KB) + L1d L#0 (32KB) + L1i L#0 (32KB) + Core L#0 + PU L#0 (P#0)
HostBridge
PCI 00:01.1 (IDE)
Block "sr0"
PCI 00:02.0 (VGA)
PCI 00:03.0 (Ethernet)
Misc(MemoryModule)
An obvious limitation is that if the binary/library requires certain data files, those will not be present in the initrd. It isn’t attempting to do anything clever like query the corresponding RPM file list and copy those. This tool is meant to be simple and fast and keep out of your way. If certain data files are critical for testing though, the --copy argument can be used. The copied files will be put at the same path inside the initrd as found on the host
$ ./make-tiny-image.py --copy /etc/redhat-release
tiny-initrd.img
6.0.8-300.fc37.x86_64
Copy extra /etc/redhat-release -> /tmp/make-tiny-imageicj1tvq4/etc/redhat-release
$ qemu-system-x86_64 \
-kernel /boot/vmlinuz-$(uname -r) \
-initrd tiny-initrd.img \
-append 'console=ttyS0 quiet' \
-m 1000 -display none -serial stdio -accel kvm
~ # cat /etc/redhat-release
Fedora release 37 (Thirty Seven)
What if the problem being tested requires using some kernel modules ? That’s covered too with the --kmod argument, which will copy in the modules listed, along with their dependencies and the insmod command itself. As an example of its utility, I used this recently to debug a regression in support for the iTCO watchdog in Linux kernels
$ ./make-tiny-image.py --kmod lpc_ich --kmod iTCO_wdt --kmod i2c_i801
tiny-initrd.img
6.0.8-300.fc37.x86_64
Copy kmod /lib/modules/6.0.8-300.fc37.x86_64/kernel/drivers/mfd/lpc_ich.ko.xz -> /tmp/make-tiny-image63td8wbl/lib/modules/lpc_ich.ko.xz
Copy kmod /lib/modules/6.0.8-300.fc37.x86_64/kernel/drivers/watchdog/iTCO_wdt.ko.xz -> /tmp/make-tiny-image63td8wbl/lib/modules/iTCO_wdt.ko.xz
Copy kmod /lib/modules/6.0.8-300.fc37.x86_64/kernel/drivers/watchdog/iTCO_vendor_support.ko.xz -> /tmp/make-tiny-image63td8wbl/lib/modules/iTCO_vendor_support.ko.xz
Copy kmod /lib/modules/6.0.8-300.fc37.x86_64/kernel/drivers/mfd/intel_pmc_bxt.ko.xz -> /tmp/make-tiny-image63td8wbl/lib/modules/intel_pmc_bxt.ko.xz
Copy kmod /lib/modules/6.0.8-300.fc37.x86_64/kernel/drivers/i2c/busses/i2c-i801.ko.xz -> /tmp/make-tiny-image63td8wbl/lib/modules/i2c-i801.ko.xz
Copy kmod /lib/modules/6.0.8-300.fc37.x86_64/kernel/drivers/i2c/i2c-smbus.ko.xz -> /tmp/make-tiny-image63td8wbl/lib/modules/i2c-smbus.ko.xz
Copy bin /usr/sbin/insmod -> /tmp/make-tiny-image63td8wbl/bin/insmod
Copy lib /lib64/libzstd.so.1 -> /tmp/make-tiny-image63td8wbl/lib64/libzstd.so.1
Copy lib /lib64/liblzma.so.5 -> /tmp/make-tiny-image63td8wbl/lib64/liblzma.so.5
Copy lib /lib64/libz.so.1 -> /tmp/make-tiny-image63td8wbl/lib64/libz.so.1
Copy lib /lib64/libcrypto.so.3 -> /tmp/make-tiny-image63td8wbl/lib64/libcrypto.so.3
Copy lib /lib64/libgcc_s.so.1 -> /tmp/make-tiny-image63td8wbl/lib64/libgcc_s.so.1
Copy lib /lib64/libc.so.6 -> /tmp/make-tiny-image63td8wbl/lib64/libc.so.6
Copy lib /lib64/ld-linux-x86-64.so.2 -> /tmp/make-tiny-image63td8wbl/lib64/ld-linux-x86-64.so.2
$ ~/src/virt/qemu/build/qemu-system-x86_64 -kernel /boot/vmlinuz-$(uname -r) -initrd tiny-initrd.img -append 'console=ttyS0 quiet' -m 1000 -display none -serial stdio -accel kvm -M q35 -global ICH9-LPC.noreboot=false -watchdog-action poweroff -trace ich9* -trace tco*
ich9_cc_read addr=0x3410 val=0x20 len=4
ich9_cc_write addr=0x3410 val=0x0 len=4
ich9_cc_read addr=0x3410 val=0x0 len=4
ich9_cc_read addr=0x3410 val=0x0 len=4
ich9_cc_write addr=0x3410 val=0x20 len=4
ich9_cc_read addr=0x3410 val=0x20 len=4
tco_io_write addr=0x4 val=0x8
tco_io_write addr=0x6 val=0x2
tco_io_write addr=0x6 val=0x4
tco_io_read addr=0x8 val=0x0
tco_io_read addr=0x12 val=0x4
tco_io_write addr=0x12 val=0x32
tco_io_read addr=0x12 val=0x32
tco_io_write addr=0x0 val=0x1
tco_timer_reload ticks=50 (30000 ms)
~ # mknod /dev/watchdog0 c 10 130
~ # cat /dev/watchdog0
tco_io_write addr=0x0 val=0x1
tco_timer_reload ticks=50 (30000 ms)
cat: read error: Invalid argument
[ 11.052062] watchdog: watchdog0: watchdog did not stop!
tco_io_write addr=0x0 val=0x1
tco_timer_reload ticks=50 (30000 ms)
~ # tco_timer_expired timeouts_no=0 no_reboot=0/1
tco_timer_reload ticks=50 (30000 ms)
tco_timer_expired timeouts_no=1 no_reboot=0/1
tco_timer_reload ticks=50 (30000 ms)
tco_timer_expired timeouts_no=0 no_reboot=0/1
tco_timer_reload ticks=50 (30000 ms)
The Linux regression had accidentally left the watchdog with the ‘no reboot’ bit set, so it would never trigger the action, which we diagnosed from seeing repeated QEMU trace events for tco_timer_expired after triggering the watchdog in the guest. This was quicky fixed by the Linux maintainers.
In spite of being such a simple and crude script, with many, many, many unhandled edge cases, it has proved remarkably useful at enabling low overhead debugging of QEMU/Linux guest behaviour.
Since the project’s creation about 14 years ago, libvirt has grown enormously. In that time there has been a lot of code refactoring, but these were always fairly evolutionary changes; there has been little revolutionary change of the overall system architecture or some core technical decisions made early on. This blog post is one of a series examining recent technical decisions that can be considered more revolutionary to libvirt. This was the topic of a talk given at KVM Forum 2019 in Lyon.
Historical driver architecture
Historically the local stateful drivers in libvirt have supported one or two modes of access
- “system mode” – privileged libvirtd running as root, global per host
- “session mode” – unprivileged libvirtd, isolated to individual non-root users
Within context of each daemon, VM name uniqueness is enforced. Operating via the daemon means that all applications connected to that same libvirtd get the same world view. This single world view is exactly what you want when dealing with server / cloud / desktop virtualization, because it means tools like ‘virt-top‘, ‘virt-viewer’, ‘virsh‘ can see the same VMs as virt-manager / oVirt / OpenStack / GNOME Boxes / etc.
There are other use cases for virtualization, however, where this single world view across applications may be much less desirable. Instead of spawning VMs for the purpose of running a full guest operating system, the VM is used as a building block for an application specific use case. I describe these use cases as “embedded virtualization”, with the libguestfs project being a well known long standing example. This uses a VM as a way to confine execution of its appliance, allowing safe manipulation of disk images. The libvirt-sandbox project is another example which provides a way to take binaries installed on the host OS and directly execute them inside a virtual machine, using 9p filesystem passthrough. More recently the Kata project aims to provide a docker compatible container runtime built using KVM.
In many, but not neccessarily all, of these applications, it is unhelpful for the KVM instances that are launched to become visible to other applications like virt-manager / OpenStack. For example if Nova sees a libguestfs VM running in libvirt it won’t be able to correlate this VM with its own world view. There have been cases where a mgmt app would try to destroy these externally launched VM in order to reconcile its world view.
There are other practicalities to consider when using a shared daemon like libvirtd. Each application has to ensure it creates a sensible unique name for each virtual machine, that won’t clash with names picked by other applications. Then there is the question of cleaning up resources such as log files left over from short lived VMs.
When spawning KVM via a separate daemon, the QEMU process is daemonized, such that it disassociated from both libvirtd and the application which spawned it. It will only be cleaned up by an explicit API call to destroy it, or by the guest application shutting it down. For embedded use cases, it would be helpful if the VM would automatically die when the application which launched it dies. Libvirt introduces a notion of “auto destroy” to associated the lifetime of a VM with the client socket connection. It would be simpler if the VM process were simply in the same process group as the application, allowing normal OS level process tree pruning. The disassociated process context means that the QEMU process also looses the cgroup & namespace placement of the application using it
An initial embedded libvirt driver
A possible answer to all these problems is to introduce the notion of an “embedded mode” for libvirt drivers. When using a libvirt driver in this mode, there is no libvirtd daemon involved, instead the libvirt driver code is loaded into the application process itself. In embedded mode the libvirt driver is operating against a custom directory prefix for reading and writing config / state files. The directory is private to each application which has an instance of the embedded driver open. Since the libvirt driver is directly loaded into the application, there is no RPC service exposed and thus there is no way to use virsh and other tools to access the driver. This is important to remember because it means there is no way to debug problems with embedded VMs using normal libvirt tools. For some applications this is acceptable as the VMs are short-lived & throw away, but for others this restriction might be unacceptable.
At the time of writing this post, support for embedded QEMU driver connections has merged to GIT master, and will be released in 6.1.0. In order to enable use of encrypted disks, there is also support for an embedded secret driver. The embedded driver feature is considered experimental initially, and so contrary to normal libvirt practice we’re not providing a strong upgrade compatibility guarantee. The API and XML formats won’t change, but the behavior of the embedded driver may still change.
Along with the embedded driver mode, is a new command line tool called virt-qemu-run. This is a simple tool using the embedded QEMU driver to run a single QEMU virtual machine, automatically exiting when QEMU exits, or tearing down QEMU if the tool exits abnormally. This can be used directly by users for self contained virtual machines, but it also serves as an example of how to use the embedded driver and has been important for measuring startup performance. This tool is also considered experimental and so its CLI syntax is subject to change in future.
In general the embedded mode drivers should offer the same range of functionality as the main system or session modes in libvirtd. To learn more about their usage and configuration, consult the three pages linked in the above paragraphs.
Further development work
During development of the embedded driver one of the problems that quickly became apparently was the time required to launch a virtual machine. When libvirtd starts up one of the things it does is to probe all installed QEMU binaries to determine what features they support. This can take 300-500 milliseconds per binary which doesn’t sound like much, but if you have all 30 QEMU binaries installed this is 10-15 seconds. The results of this probing are cached, avoiding repeated performance hits until something changes which would invalidate the information. The caching doesn’t help the embedded driver case though, because it is using a private directory tree for state and thus doesn’t see the cache from the system / session mode drivers. To deal with this problem the QEMU driver startup process was significantly refactored such that probing of QEMU binaries is delayed until the data is actually needed. This massively helps both the new embedded mode and existing system/session modes.
Unfortunately it is fairly common for applications to query the libvirt host capabilities and the returned data is required to report on all QEMU binaries, thus triggering the slow probing operation. There is a new API which allows probing of a single QEMU binary which applications are increasingly using, but there are still valid use cases for the general host capabilities information. To address the inherent design limitations of the current API, one or more replacements are required to allow more targetted information reporting to avoid the mass QEMU probe.
Attention will then need to switch to optimizing the startup procedure for spawning QEMU. There is one key point where libvirt uses QMP to ask the just launched QEMU what CPU features it has exposed to the guest OS. This results in a huge number of QMP calls, one for each CPU feature. This needs to be optimized, ideally down to 1 single QMP call, which might require QEMU enhancements to enable libvirt to get the required information more efficiently.
One of the goals of the embedded driver is to have the QEMU process inherit the application’s process context (cgroups, namespaces, CPU affinity, etc) by default and keep QEMU as a child of the application process. This does not currently happen as the embedded driver is re-using the existing startup code which moves QEMU into dedicated cgroups and explicitly resets CPU affinity, as well as daemonizing QEMU. The need to address these problems is one of the reasons the embedded mode is marked experimental with behaviour subject to change.
Since the project’s creation about 14 years ago, libvirt has grown enormously. In that time there has been a lot of code refactoring, but these were always fairly evolutionary changes; there has been little revolutionary change of the overall system architecture or some core technical decisions made early on. This blog post is one of a series examining recent technical decisions that can be considered more revolutionary to libvirt. This was the topic of a talk given at KVM Forum 2019 in Lyon.
Monolithic daemon
Anyone who has used libvirt should be familiar with the libvirtd daemon which runs most of the virtualization and secondary drivers that libvirt distributes. Only a few libvirt drivers are stateless and run purely in the library. Internally libvirt has always tried to maintain a fairly modular architecture, with each hypervisor driver being a separated from other drivers. There are also secondary drivers providing storage, network, firewall functionality which are notionally separate from all the virtualization drivers. Over time the separation has broken down with hypervisor drivers directly invoking internal methods from the secondary drivers, but last year there was a major effort to reverse this and re-gain full separation between every driver.
There are various problems with having a monolithic daemon like libvirtd. From a security POV, it is hard to provide any meaningful protections to libvirtd. The range of functionality it exposes, provides an access level that is more or less equivalent to having a root shell. So although libvirtd runs with a “virtd_t” SELinux context, this should be considered little better than running “unconfined_t“. As well as providing direct local access to the APIs, the libvirtd daemon also has the job of exposing remote access over TCP, most commonly needed when doing live migration. Exposing the drivers directly over TCP is somewhat undesirable given the size of the attack surface they have.
The biggest problems users have seen are around reliability of the daemon. A bug in any single driver in libvirt can impact on the functionality of all other drivers. As an example, if something goes wrong in the libvirt storage mgmt APIs, this can harm management of any QEMU VMs. Problems can be things like crashes of the daemon due to memory corruption, or more subtle things like main event loop starvation due to long running file handle event callbacks, or accidental resource cleanup such as closing a file descriptor belonging to another thread.
Libvirt drivers are shipped as loadable modules, and an installation of libvirt does not have to include all drivers. Thus a minimal installation of libvirt is a lot smaller than users typically imagine it is. The existance of the monolithic libvirtd daemon, however, and the fact the many apps pull in broader RPM dependencies than they truly need, results in a perception that libvirt is bloated / heavyweight.
Modular daemons
With all this in mind, libvirt has started a move over to a new modular daemon model. In this new world, each driver in libvirt (both hypervisor drivers & secondary drivers) will be serviced by its own dedicated daemon. So there will be a “virtqemud“, “virtxend“, “virtstoraged“, “virtnwfilterd“, etc. Each of these daemons will only support access via a dedicated local UNIX domain socket, /run/libvirt/$DAEMONNAME, eg /run/libvirt/virtqemud. The libvirt client library will be able to connect to either the old monolithic daemon socket path /run/libvirt/libvirt-sock, or the new per-daemon socket. The hypervisor daemons will be able to open connections to the secondary daemons when required by requested functionality, eg to config a firewall for a QEMU guest NIC.
Remote off-host access to libvirt functionality will be handled via a new virtproxyd daemon which listens for TCP connections and forwards API calls over a local UNIX socket to whichever modular daemon needs to service it. This proxy daemon will also be responsible for handling the monolithic daemon UNIX domain socket path that old libvirt clients will be expecting to use.
Overall from an application developer POV, the change to monolithic daemons will be transparent at the API level. The main impact will be on deployment tools like Puppet / Ansible seeking to automate deployment of libvirt, which will need to be aware of these new daemons and their config files. The resulting architecture should be more reliable in operation and enable development of more restrictive security policies.
Both the existing libvirtd and the new modular daemons have been configured to make use of systemd socket activation and auto-shutdown after a timeout, so the daemons should only be launched when they actually need to do some work. Several daemons will still need to startup at boot to activate various resources (create the libvirt virb0 bridge device, or auto-start VMs), but should stop quickly once this is done.
Migration timeframe
At the time of writing the modular daemons exist in libvirt releases and are built and installed by default. The libvirt client library, however, still defaults to connecting to the monolithic libvirtd UNIX socket. To best of my knowledge, all distros with systemd use presets which favour the monolithic daemon too. IOW, thus far, nothing has changed from most user’s POV. In the near future, however, we intend to flip the switch in the build system such that the libvirt client library favours connections to the modular daemons, and encourage distros to change their systemd presets to match.
The libvirtd daemon will remain around, but deprecated, for some period of time before it is finally deleted entirely. When this deletion will happen is still TBD, but it is not less than 1 year away, and possibly as much as 2 years. The decision will be made based on how easily & quickly applications find adaptation to the new modular daemon world.
Future benefits
The modular daemon model opens up a number of interesting possibilities for addressing long standing problems with libvirt. For example, the QEMU driver in libvirt can operate in “system mode” where it is running as root and can expose all features of QEMU. There is also the “session mode” where it runs as an unprivileged user but with features dramatically reduced. For example, no firewall integration, drastically reduced network connectivity options, no PCI device assignment and so on. With the modular daemon model, a new hybrid approach is possible. A “session mode” QEMU driver can be enhanced to know how to talk to a “system mode” host device driver to do PCI device assignment (with suitable authentication prompts of course), likewise for network connectivity. This will make the unprivileged “session mode” QEMU driver a much more compelling choice for applications such as virt-manager or GNOME Boxes which prefer to run fully unprivileged.
Since the project’s creation about 14 years ago, libvirt has grown enormously. In that time there has been a lot of code refactoring, but these were always fairly evolutionary changes; there has been little revolutionary change of the overall system architecture or some core technical decisions made early on. This blog post is one of a series examining recent technical decisions that can be considered more revolutionary to libvirt. This was the topic of a talk given at KVM Forum 2019 in Lyon.
Historical usage
In common with many projects which have been around for a similar time frame, libvirt has accumulated a variety of different programming languages and document formats, for a variety of tasks.
The main library is written in C, but around that there is the autotools build system which adds shell, make, autoconf, automake, libtool, m4, and other utilities like sed, awk, etc. Then there are many helper scripts used for code generation or testing which are variously written in shell, perl or python. For documentation, there are man pages written in POD, web docs written in HTML5 with an XSL templating system, and then some docs written in XML which generate HTML, and some docs generated from source code comments. Finally there are domain specific languages such as XDR for the RPC system.
There are a couple of issues with the situation libvirt finds itself in. The large number of different languages and formats places a broad knowledge burden on new contributors to the project. Some of the current choices are now fairly obscure & declining in popularity, thus not well known by potential project contributors. For example, Markdown and reStructuredText (RST) are more commonly known than Perl’s POD format. Developers are more likely to be competent in Python than in Perl. Some of the languages libvirt uses are simply too hard to deal with, for example it is a struggle to find anyone who can explain m4 or enjoys using it when writing configure scripts for autoconf.
Ultimately the issues all combine to have a couple of negative effects on the project. They drive away potential new contributors due to their relative obscurity. They reduce the efficiency of existing contributors due to their poor suitability for the tasks they are applied to.
Intended future usage
With the above problems in mind, there is a desire to consolidate and update the programming languages and document formats that libvirt uses. The goals are to reduce the knowledge burden on contributors, and simplify the development experience to make it easier to get the important work done. Approximately the intention is to get to a place where libvirt uses C for the core library code, Python for all helper scripts, RST for all documentation, and Meson for the build system. This should eliminate the use of shell, shell utilities like sed/awk, perl, POD, XSL, HTML5, m4, make, autoconf, automake. A decision about which static website builder to use to replace XSL hasn’t been made yet, but Sphinx and Pelican are examples of the kind of tools being considered. Getting to this desired end point will take a prolonged effort, but setting a clear direction now will assist contributors in understanding where to best spend time.
To kickstart this consolidation at the end of last year almost all of the Perl build scripts were converted to Python. This was a manual line-by-line conversion, so the structure of the scripts didn’t really change much, just the minimal language syntax changes in most cases. There are still a handful of Perl scripts remaining, which are some of the most complicated ones. These really need a rewrite, rather than a plain syntax conversion, so will take more time to bring over to Python. The few shell scripts have also been converted to Python, with more to follow. After that all the POD man pages were fed through a automated conversion pipeline to create RST formatted man pages. In doing this, the man pages are now also published online as part of the libvirt website. Some of the existing HTML content has also been converted into RST.
The next really big step is converting the build system from autotools into Meson. This will eliminate some of the most complex, buggy and least understood parts of libvirt. It will be refreshing to have a build system which only requires knowledge of a single high level domain specific language, with Python for extensions, instead of autotools which requires knowledge of at least 6 different languages and the interactions between them.