I’m pleased to announce a new release of GTK-VNC, version 0.7.2. The release focus is on bug fixing, and addresses an important regression in TLS handling from the previous release.
- Deprecated the manual python2 binding in favour of GObject introspection. It will be deleted in the next release.
- Emit led state notification on connect
- Fix incorrect copyright notices
- Simplify shifted-tab key handling
- Don’t short circuit TLS credential request
- Improve check for keymap under XWayland
- Update doap description of project
- Modernize RPM specfile
Thanks to all those who reported bugs and provides patches that went into this new release.
With libvirt releasing 11 times a year and QEMU releasing three times a year, there is a quite large set of historical releases available by now. Both projects have a need to maintain compatibility across releases in varying areas. For QEMU the most important thing is that versioned machine types present the same guest ABI across releases. ie a ‘pc-2.0.0’ machine on QEMU 2.0.0, should be identical to a ‘pc-2.0.0’ machine on QEMU 2.5.0. If this rule is violated, the ability to live migrate and save/restore is doomed. For libvirt the most important thing is that a given guest configuration should be usable across many QEMU versions, even if the command line arguments required to achieve the configuration in QEMU have changed. This is key to libvirt’s promise that upgrading either libvirt or QEMU will not break either previously running guests, or future operations by the management tool. Finally management applications using libvirt may promise that they’ll operate with any version of libvirt or QEMU from a given starting version onwards. This is key to ensuring a management application can be used on a wide range of distros each with different libvirt/QEMU versions. To achieve this the application must be confident it hasn’t unexpectedly made use of a feature that doesn’t exist in a previous version of libvirt/QEMU that is intended to be supported.
The key to all this is of course automated testing. Libvirt keeps a record of capabilities associated with each QEMU version in its GIT repo along with various sample pairs of XML files and QEMU arguments. This is good for unit testing, but there’s some stuff that’s only really practical to validate well by running functional tests against each QEMU release. For live migration compatibility, it is possible to produce reports specifying the guest ABI for each machine type, on each QEMU version and compare them for differences. There are a huge number of combinations of command line args that affect ABI though, so it is useful to actually have the real binaries available for testing, even if only to dynamically generate the reports.
The COPR repository
With the background motivation out of the way, lets get to the point of this blog post. A while ago I created a Fedora copr repository that contained many libvirt builds. These were created in a bit of a hacky way making it hard to keep it up to date as new releases of libvirt come out, or as new Fedora repos need to be targeted. So in the past week, I’ve done a bit of work to put this on a more sustainable footing and also integrate QEMU builds.
As a result, there is a now a copr repo called ‘virt-ark‘ that currently targets Fedora 26 and 27, containing every QEMU version since 1.4.0 and every libvirt version since 1.2.0. That is 46 versions of libvirt dating back to Dec 2013, and 36 versions of QEMU dating back to Feb 2013. For QEMU I included all bugfix releases, which is why there are so many when there’s only 3 major releases a year compared to libvirt’s 11 major versions a year.
# rpm -qa | grep -E '(libvirt|qemu)-ark' | sort
libvirt-ark-1_2_0-1.2.0-1.x86_64
libvirt-ark-1_2_10-1.2.10-2.fc27.x86_64
libvirt-ark-1_2_11-1.2.11-2.fc27.x86_64
...snip...
libvirt-ark-3_8_0-3.8.0-2.fc27.x86_64
libvirt-ark-3_9_0-3.9.0-2.fc27.x86_64
libvirt-ark-4_0_0-4.0.0-2.fc27.x86_64
qemu-ark-1_4_0-1.4.0-3.fc27.x86_64
qemu-ark-1_4_1-1.4.1-3.fc27.x86_64
qemu-ark-1_4_2-1.4.2-3.fc27.x86_64
...snip....
qemu-ark-2_8_1-2.8.1-3.fc27.x86_64
qemu-ark-2_9_0-2.9.0-2.fc27.x86_64
qemu-ark-2_9_1-2.9.1-3.fc27.x86_64
Notice how the package name includes the version string. Each package version installs into /opt/$APP/$VERSION, eg /opt/libvirt/1.2.0 or /opt/qemu/2.4.0, so you can have them all installed at once and happily co-exist.
Using the custom versions
To launch a particular version of libvirtd
$ sudo /opt/libvirt/1.2.20/sbin/libvirtd
The libvirt builds store all their configuration in /opt/libvirt/$VERSION/etc/libvirt, and creates UNIX sockets in /opt/libvirt/$VERSION/var/run so will (mostly) not conflict with the main Fedora installed libvirt. As a result though, you need to use the corresponding virsh binary to connect to it
$ /opt/libvirt/1.2.20/bin/virsh
To test building or running another app against this version of libvirt set some environment variables
export PKG_CONFIG_PATH=/opt/libvirt/1.2.20/lib/pkgconfig
export LD_LIBRARY_PATH=/opt/libvirt/1.2.20/lib
For libvirtd to pick up a custom QEMU version, it must appear in $PATH before the QEMU from /usr, when libvirtd is started eg
$ su -
# export PATH=/opt/qemu/2.0.0/bin:$PATH
# /opt/libvirt/1.2.20/sbin/libvirtd
Alternatively just pass in the custom QEMU binary path in the guest XML (if the management app being tested supports that).
The build mechanics
When managing so many different versions of a software package you don’t want to be doing lots of custom work to create each one. Thus I have tried to keep everything as simple as possible. There is a Pagure hosted GIT repo containing the source for the builds. There are libvirt-ark.spec.in and qemu-ark.spec.in RPM specfile templates which are used for every version. No attempt is made to optimize the dependencies for each version, instead BuildRequires will just be the union of dependencies required across all versions. To keep build times down, for QEMU only the x86_64 architecture system emulator is enabled. In future I might enable the system emulators for other architectures that are commonly used (ppc, arm, s390), but won’t be enabling all the other ones QEMU has. The only trouble comes when newer Fedora releases include a change which breaks the build. This has happened a few times for both libvirt and QEMU. The ‘patches/‘ subdirectory thus contains a handful of patches acquired from upstream GIT repos to fix the builds. Essentially though I can run
$ make copr APP=libvirt ARCHIVE_FMT=xz DOWNLOAD_URL=https://libvirt.org/sources/ VERSION=1.3.0
Or
$ make copr APP=qemu ARCHIVE_FMT=xz DOWNLOAD_URL=https://download.qemu.org/ VERSION=2.6.0
And it will download the pristine upstream source, write a spec file including any patches found locally, create a src.rpm and upload this to the copr build service. I’ll probably automate this a little more in future to avoid having to pass so many args to make, by keeping a CSV file with all metadata for each version.
In recent times I have been aggressively working to expand the coverage of libvirt XML schemas in the libvirt-go-xml project. Today this work has finally come to a conclusion, when I achieved what I believe to be effectively 100% coverage of all of the libvirt XML schemas. More on this later, but first some background on Go and XML….
For those who aren’t familiar with Go, the core library’s encoding/xml module provides a very easy way to consume and produce XML documents in Go code. You simply define a set of struct types and annotate their fields to indicate what elements & attributes each should map to. For example, given the Go structs:
type Person struct {
XMLName xml.Name `xml:"person"`
Name string `xml:"name,attr"`
Age string `xml:"age,attr"`
Home *Address `xml:"home"`
Office *Address `xml:"office"`
}
type Address struct {
Street string `xml:"street"`
City string `xml:"city"`
}
You can parse/format XML documents looking like
<person name="Joe Blogs" age="24">
<home>
<street>Some where</street><city>London</city>
</home>
<office>
<street>Some where else</street><city>London</city>
</office>
</person>
Other programming languages I’ve used required a great deal more work when dealing with XML. For parsing, there’s typically a choice between an XML stream based parser where you have to react to tokens as they’re parsed and stuff them into structs, or a DOM object hierarchy from which you then have to pull data out into your structs. For outputting XML, apps either build up a DOM object hierarchy again, or dynamically format the XML document incrementally. Whichever approach is taken, it generally involves writing alot of tedious & error prone boilerplate code. In most cases, the Go encoding/xml module eliminates all the boilerplate code, only requiring the data type defintions. This really makes dealing with XML a much more enjoyable experience, because you effectively don’t deal with XML at all! There are some exceptions to this though, as the simple annotations can’t capture every nuance of many XML documents. For example, integer values are always parsed & formatted in base 10, so extra work is needed for base 16. There’s also no concept of unions in Go, or the XML annotations. In these edge cases custom marshaling / unmarshalling methods need to be written. BTW, this approach to XML is also taken for other serialization formats including JSON and YAML too, with one struct field able to have many annotations so it can be serialized to a range of formats.
Back to the point of the blog post, when I first started writing Go code using libvirt it was immediately obvious that everyone using libvirt from Go would end up re-inventing the wheel for XML handling. Thus about 1 year ago, I created the libvirt-go-xml project whose goal is to define a set of structs that can handle documents in every libvirt public XML schema. Initially the level of coverage was fairly light, and over the past year 18 different contributors have sent patches to expand the XML coverage in areas that their respective applications touched. It was clear, however, that taking an incremental approach would mean that libvirt-go-xml is forever trailing what libvirt itself supports. It needed an aggressive push to achieve 100% coverage of the XML schemas, or as near as practically identifiable.
Alongside each set of structs we had also been writing unit tests with a set of structs populated with data, and a corresponding expected XML document. The idea for writing the tests was that the author would copy a snippet of XML from a known good source, and then populate the structs that would generate this XML. In retrospect this was not a scalable approach, because there is an enourmous range of XML documents that libvirt supports. A further complexity is that Go doesn’t generate XML documents in the exact same manner. For example, it never generates self-closing tags, instead always outputting a full opening & closing pair. This is semantically equivalent, but makes a plain string comparison of two XML documents impractical in the general case.
Considering the need to expand the XML coverage, and provide a more scalable testing approach, I decided to change approach. The libvirt.git tests/ directory currently contains 2739 XML documents that are used to validate libvirt’s own native XML parsing & formatting code. There is no better data set to use for validating the libvirt-go-xml coverage than this. Thus I decided to apply a round-trip testing methodology. The libvirt-go-xml code would be used to parse the sample XML document from libvirt.git, and then immediately serialize them back into a new XML document. Both the original and new XML documents would then be parsed generically to form a DOM hierarchy which can be compared for equivalence. Any place where documents differ would cause the test to fail and print details of where the problem is. For example:
$ go test -tags xmlroundtrip
--- FAIL: TestRoundTrip (1.01s)
xml_test.go:384: testdata/libvirt/tests/vircaps2xmldata/vircaps-aarch64-basic.xml: \
/capabilities[0]/host[0]/topology[0]/cells[0]/cell[0]/pages[0]: \
element in expected XML missing in actual XML
This shows the filename that failed to correctly roundtrip, and the position within the XML tree that didn’t match. Here the NUMA cell topology has a ‘<pages>‘ element expected but not present in the newly generated XML. Now it was simply a matter of running the roundtrip test over & over & over & over & over & over & over……….& over & over & over, adding structs / fields for each omission that the test identified.
After doing this for some time, libvirt-go-xml now has 586 structs defined containing 1816 fields, and has certified 100% coverage of all libvirt public XML schemas. Of course when I say 100% coverage, this is probably a lie, as I’m blindly assuming that the libvirt.git test suite has 100% coverage of all its own XML schemas. This is certainly a goal, but I’m confident there are cases where libvirt itself is missing test coverage. So if any omissions are identified in libvirt-go-xml, these are likely omissions in libvirt’s own testing.
On top of this, the XML roundtrip test is set to run in the libvirt jenkins and travis CI systems, so as libvirt extends its XML schemas, we’ll get build failures in libvirt-go-xml and thus know to add support there to keep up.
In expanding the coverage of XML schemas, a number of non-trivial changes were made to existing structs defined by libvirt-go-xml. These were mostly in places where we have to handle a union concept defined by libvirt. Typically with libvirt an element will have a “type” attribute, whose value then determines what child elements are permitted. Previously we had been defining a single struct, whose fields represented all possible children across all the permitted type values. This did not scale well and gave the developer no clue what content is valid for each type value. In the new approach, for each distinct type attribute value, we now define a distinct Go struct to hold the contents. This will cause API breakage for apps already using libvirt-go-xml, but on balance it is worth it get a better structure over the long term. There were also cases where a child XML element previously represented a single value and this was mapped to a scalar struct field. Libvirt then added one or more attributes on this element, meaning the scalar struct field had to turn into a struct field that points to another struct. These kind of changes are unavoidable in any nice manner, so while we endeavour not to gratuitously change currently structs, if the libvirt XML schema gains new content, it might trigger further changes in the libvirt-go-xml structs that are not 100% backwards compatible.
Since we are now tracking libvirt.git XML schemas, going forward we’ll probably add tags in the libvirt-go-xml repo that correspond to each libvirt release. So for app developers we’ll encourage use of Go vendoring to pull in a precise version of libvirt-go-xml instead of blindly tracking master all the time.
Quite by chance today I discovered that Fedora 27 can display full colour glyphs for unicode characters that correspond to emojis, when the terminal displaying my mutt mail reader displayed someone’s name with a full colour glyph showing stars:

Mutt in GNOME terminal rendering color emojis in sender name
Chatting with David Gilbert on IRC I learnt that this is a new feature in Fedora 27 GNOME, thanks to recent work in the GTK/Pango stack. David then pointed out this works in libvirt, so I thought I would illustrate it.
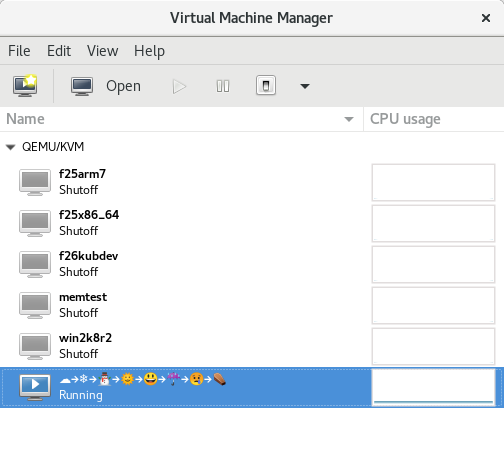
Virtual machine name with full colour emojis rendered
No special hacks were required to do this, I simply entered the emojis as the virtual machine name when creating it from virt-manager’s wizard
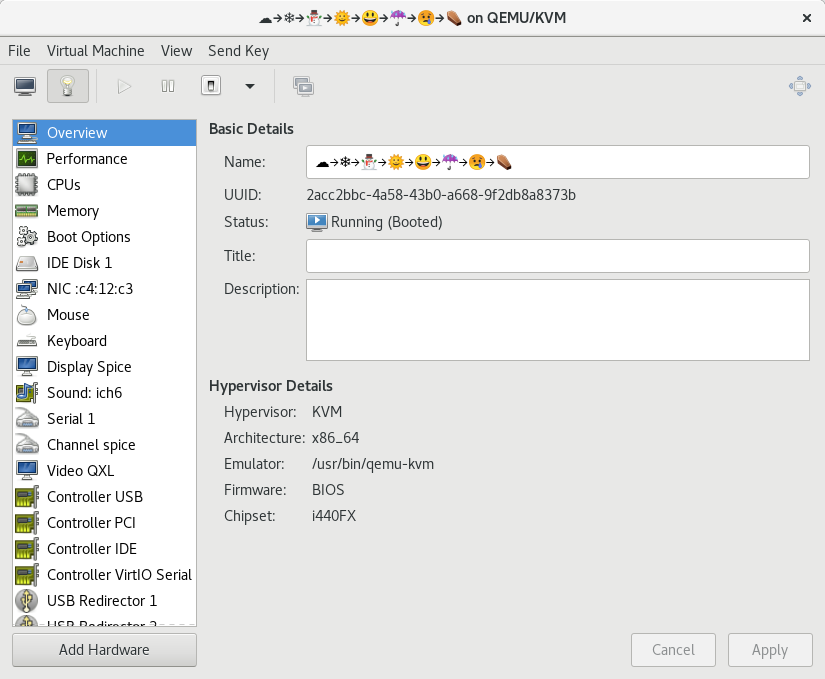
Virtual machine name with full colour emojis rendered
As mentioned previously, GNOME terminal displays colour emojis, so these virtual machine names appear nicely when using virsh and other command line tools
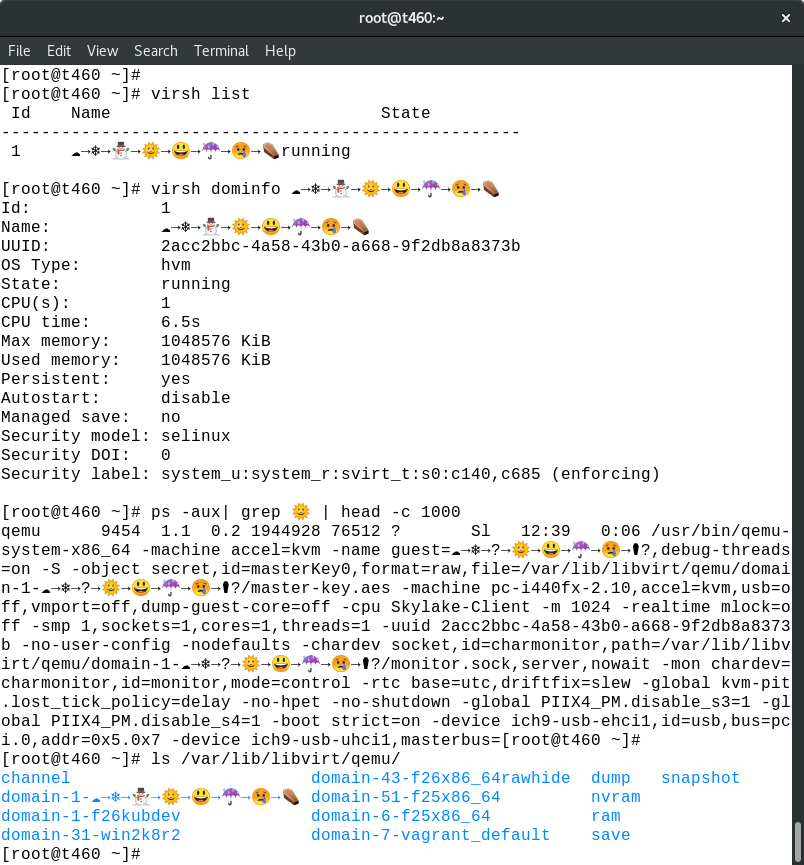
Virtual machine name rendered with full colour emojis in terminal commands
The more observant readers will notice that the command line args have a bug as the snowman in the machine name is incorrectly rendered in the process listing. The actual data in /proc/$PID/cmdline is correct, so something about the “ps” command appears to be mangling it prior to output. It isn’t simply a font problem because other comamnds besides “ps” render properly, and if you grep the “ps” output for the snowman emoji no results are displayed.
I am pleased to announce a new release 1.0 of Entangle is available for download from the usual location:
https://entangle-photo.org/download/
This release brings some significant changes to the application build system and user interface
- Requires Meson + Ninja build system instead of make
- Switch to 2-digit version numbering
- Fix corruption of display when drawing session browser
- Register application actions for main operations
- Compile UI files into binary
- Add a custom application menu
- Switch over to using header bar, instead of menu bar and tool bar.
- Enable close button for about dialog
- Ensure plugin panel fills preferences dialog
- Tweak UI spacing in supported cameras dialog
- Add keyboard shortcuts overlay